
多线程下的缓存优化
项目背景
在写Raytracer或者Rasterizer的时候,由于每个像素之间的计算是可以做到相互独立的,所以一个常见的优化便是开启多线程来进行加速,这样的话便不会说出现一核有难,多核围观的情况。但是,多线程启动后,我们需要额外关注对于全局状态的访问,并且尽可能的提高程序的cache友好性。
不过这次主要是对Finding and Fixing Slow Code // Ray Tracing series的一个记录,下面的代码是记录当光线击中物体时进行反射的一个情况,在测试的时候,发现Random::vec3()这个函数开销非常大,大概总时间的50%都是在算Random,这个说实话确实不太合理。
1 | ray.Origin = payload.WorldPosition + payload.WorldNormal * 0.0001f; |
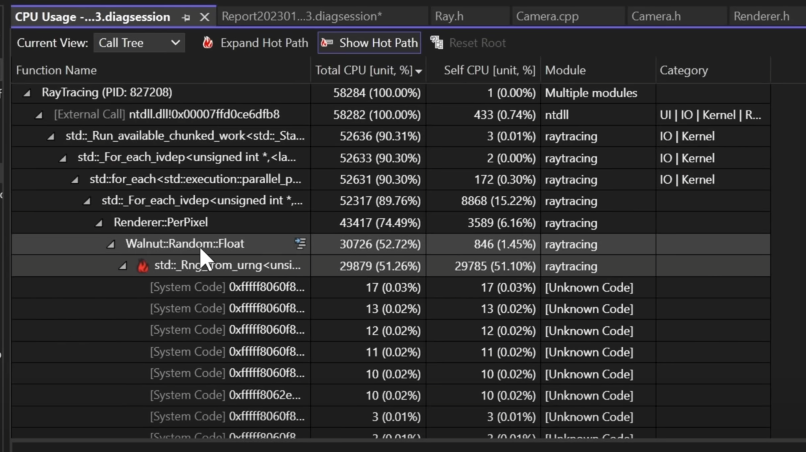
在找到重点问题后,我们便可以开始着手优化,这也就是所谓的benchmark first,then optimize。
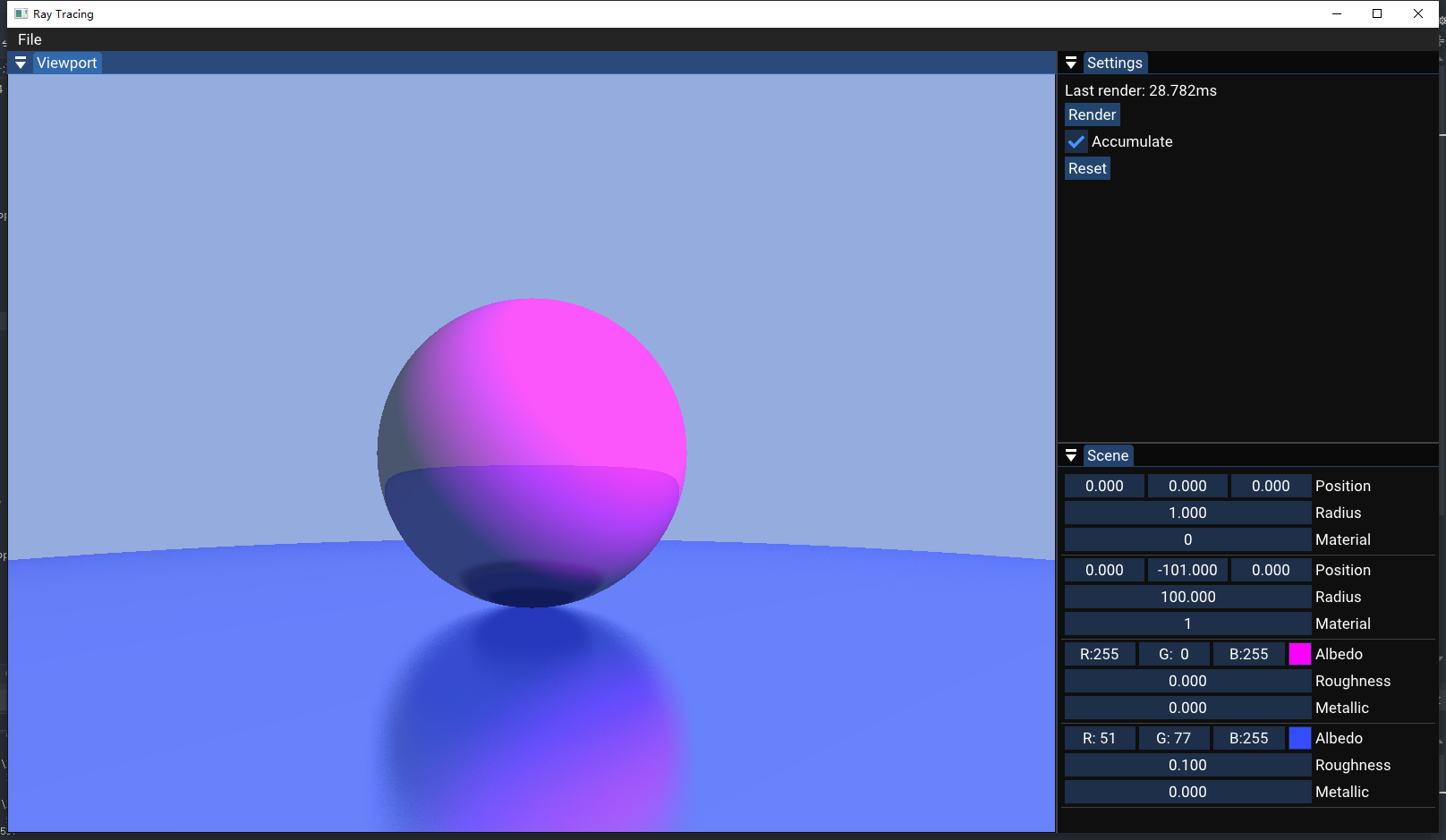
并且记录下未优化情况下的render time, 大概是28ms左右
具体措施
这个Random库的实现是非常简单的那一类,本身只是对std::random的一个简单封装,里面有一个random engine以及一个简单的std::uniform_int_distribution。
1 | static std::mt19937 s_RandomEngine; |
而我们所使用的这个Random::Vec3()的实现如下。
1 | static float Float() |
总的来看这个实现非常正常,并没有什么明显的性能缺陷。但是如果我们继续查看这个std::mt19937的实现的话,我们就可以发现在多线程下我们不能这么简单的使用这个算法,否则的话就会造成较大的性能损失。
1 | _NODISCARD result_type operator()() { |
在关键的operator()重载中,我们可以看到实际上std::mt19937是保存了一个内部状态,然后通过this指针以及index来进行访问。而这也就回到了我们一开始所说的,当多线程环境下,我们要注意对于全局状态的访问,当一堆线程疯狂的访问这个状态数组时,我们可以想到一定是一个cache miss地狱,在我的cpu,也就是intel的实现中,cpu的每个核共享l3 cache, 然后自己的l1, l2 cache是每个核所私有的。
于是一想,我们便会考虑到如果我们让每个核都私有这个状态数组那么会怎么样呢?这在C++也很容易尝试,我们将random engine声明如下,加上thread_local关键字。
1 | static thread_local std::mt19937 s_RandomEngine; |
然后再次运行,我们看看结果如何
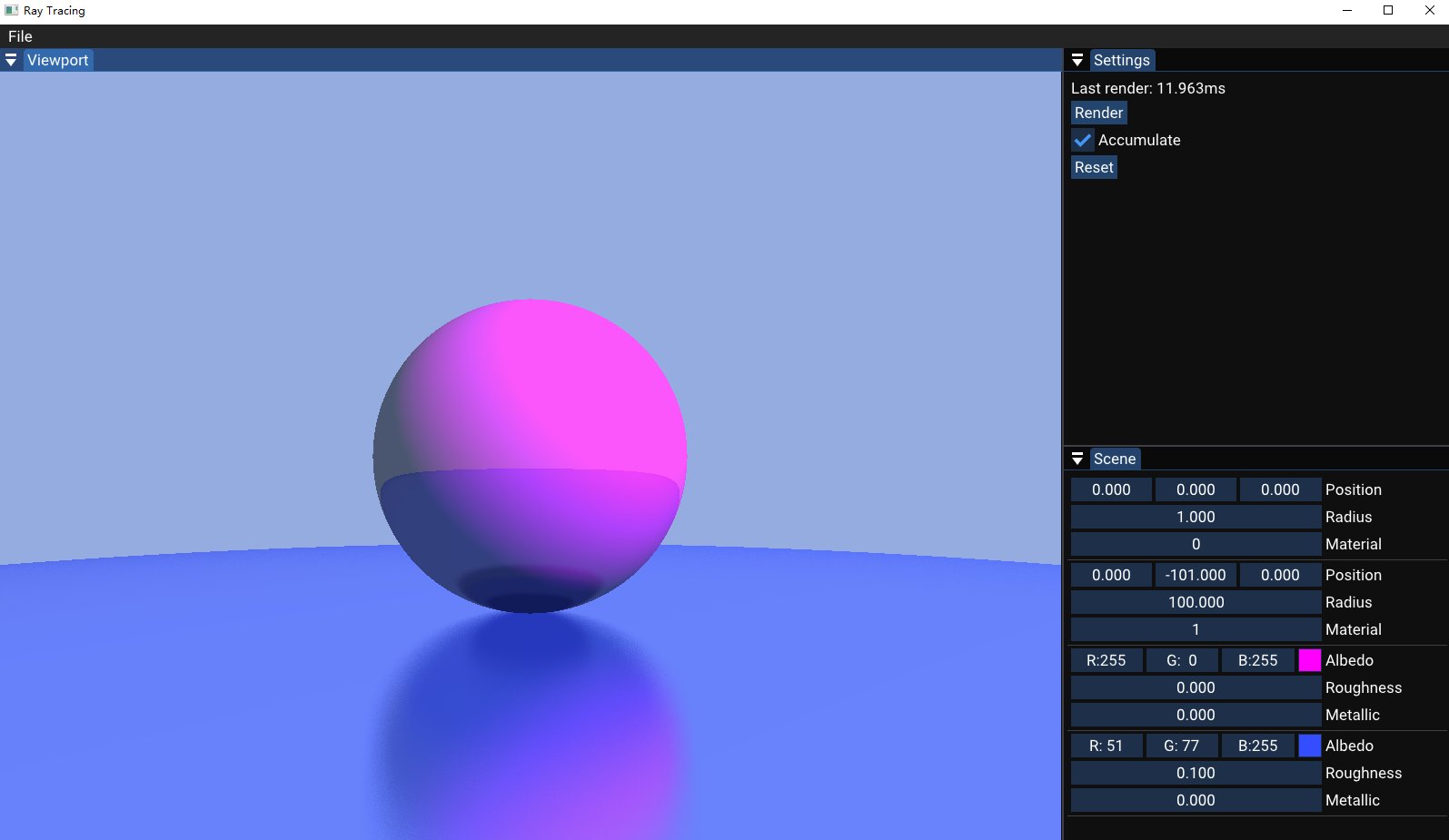
渲染时间从28ms左右下降到了11ms左右,也就是我们的假设的确是正确的,也证明了一开始的结论,我们必须要关注多线程下的访存优化,只有这样才能真正的利用好现代Cpu的多核架构。